Bosun is a significant piece of our monitoring infrastructure at Stack Overflow. In forums such as Bosun’s Slack Chat Room, we are frequently asked to describe how Bosun is set up in our environment.. This is a detailed post about our architecture surrounding Bosun. This is not the only way to set things up and may not always be the best way either – but this is our current setup.
The Pieces
There are a lot of components we use with Bosun, but they all serve their purposes in our monitoring infrastructure. The following table outlines them.
| Bosun | Alerting System | Expression language for evaluating time series from OpenTSDB, Graphite, Elastic, and InfluxDB |
| Templates for rich notifications: HTML, Graphs, Tables, CSS-inlining | ||
| Web interface for viewing alerts, writing expressions, graphing, creating alerts and templates, and testing alerts over history. | ||
| A store for metric metadata and string data about tags (for example, host IPs, Serial numbers, etc) | ||
| scollector | Collection Agent | Runs on Windows and Linux. Polls local OS and applications via APIs; also polls external services via SNMP, ICMP, etc. |
| With no configuration, monitors anything it auto-discovers (IIS, Redis, Elastic, Etc); configuration rarely needed. | ||
| BosunReporter.NET | App Metrics | Sends application metrics to bosun. |
| OpenTSDB | Time Series Database Daemon | Takes time series data and stores it in HBase |
| Time series are tagged, so it is a multi-dimensional time series database | ||
| Opserver | Monitoring dashboard | Pulls from SolarWinds Orion or Bosun |
| Also includes indepth independent monitoring and control of Redis, SQL Server, HAProxy, and Elastic | ||
| Grafana | User Dashboards | Uses the [Grafana Bosun plugin](https://github.com/grafana/grafana-plugins/tree/master/datasources/bosun) to create graphs and tables via Bosun expressions |
| TPS | Parses Web Logs | Sends raw logs to SQL and summaries in time series format to Bosun. |
| tsdbrelay | Relay Time Series and Meta Data | Cross replicates time series and meta data across data centers |
| Creates denormalized OpenTSDB metrics for faster querying speed | ||
| HBase | Where OpenTSDB Stores Data | Hadoop: The distributed filed system (HDFS), MapReduce framework, and Cluster Management (Zookeeper). |
| HBase: A clone of Google's Bigtable runs on top of Hadoop | ||
| Cloudera Manager: What we use to manage HBase | ||
| HAProxy | Load Balancer Used at Stack | We use it in front of Bosun, OpenTSDB daemons, and tsdbrelay |
| Redis | In-memory Store | *Optionally* used by Bosun to store state, metadata, metric indexes, etc. If Redis is not used, a built-in implementation in Go called LedisDB is used |
| Elastic | Document Searching | Where we send system logs. Can be queried with Bosun expressions. The Bosun Grafana plugin can use this method to graph time series info about the logs as well. |
Metric and Query Flow
Metrics are collected many ways:
- Our homegrown applications calculate their own metrics and send them to Bosun. C# programs use BosunReporter.NET and Go programs use the Go collect package.
- scollector gathers stats from the OS, services it auto-discovers.
- Network equipment and other devices must be polled from a third-party machine since they can not run scollector. We designate 2 hosts to run scollector with polling mode enabled. They collect data via SNMP (network devices), ICMP pings, and can be expanded via plug-ins.
No matter how data is collected, it is not send it directly to Bosun. They send to tsdbrelays which have two purposes:
- They relay the data to two different bosun clusters. (more on that later)
- They denormalize certain datapoints.
They actually do not send directly to tsdbrelay. We front-end tsdbrelay through a load balancer (HAProxy) so that we can scale horizontally.
We also front-end the Bosun service itself for the same reason. One Bosun server is in read-only mode, and flipping between the two requires us to sync the state and take the other bosun out of read only mode. OpenTSDB performance is improved if all write requests go to the same node and our HAProxy setup allows us to funnel all write requests to a single node when all nodes are up.
Many different systems query the time series database. We call this the “query flow”:
- Grafana: Queries OpenTSDB using Bosun expressions via
/api/expr. It can also query Elastic directly, as well as query Elastic via: Grafana -> Bosun -> Elastic. - Opserver: Queries Bosun’s
/api/hostendpoint and also queries OpenTSDB directly. - Bosun itself: when running alerts, or users interact with the UI, it queries OpenTSDB or Elastic (if it exists)

Our OpenTSDB and HBase Setup
In our main datacenter in NY to we have two HBase clusters. One is a three node cluster running on NY-TSDB0{1,2,3}. The other is a local replica running on NY-BOSUN01. The local replica is for backups (See how we Backup below).
In our secondary datacenter (named “CO”) we have a three node cluster that is a mirror setup of the NY-TSDB cluster. The HBase clusters don’t replicate across datacenters, rather tsdbrelay relays the datapoints to each independent data store.
We use a HDFS replication factor of 3 in the two main HBase clusters. The HBase replica is currently a single machine, so it has no HDFS replication.
 We use Cloudera Manager to manage our OpenTSDB clusters. We have found that HBase can be stable, but it is difficult for a shop that doesn’t happen to use it anywhere else.
We use Cloudera Manager to manage our OpenTSDB clusters. We have found that HBase can be stable, but it is difficult for a shop that doesn’t happen to use it anywhere else.
The Numbers
- 3.7 Billion datapoints a day (43,000 Datapoints a second) per cluster
- ~8 Gigabytes a day of HDFS unreplicated growth per cluster (24GB replicated)
- Currently ~ 7TB of replicated storage consumed
OpenTSDB Appends vs Compaction
HBase was very unstable when we first started using it in 2015. The main thing that improved our stability was to switch to OpenTSDB’s “appends model” instead of the “hourly compactions model”. (Note: These are unrelated to HBase compactions).
OpenTSDB stores time series as metric+tags in hourly rows. By storing them as per-hour, OpenTSDB only needs to store the delta (the offset from the base hour) for each datapoint. This is more space-efficient.
In the appends model, storing new datapoints only requires appending to the row. However this requires HBase to read the existing data block, then write it out again with the new datapoint appended. This generates a lot of network traffic.
In the compaction model, it writes the data in a less efficient form but one that requires less network bandwidth. Once each hour it then rewrites the data in the more compact, delta, format. As a result the network activity is reduced to an hourly burst instead of constant reading and rewriting.
In this graph you can see the Append Model’s network traffic load versus Hourly Compaction’s greatly reduced network load.
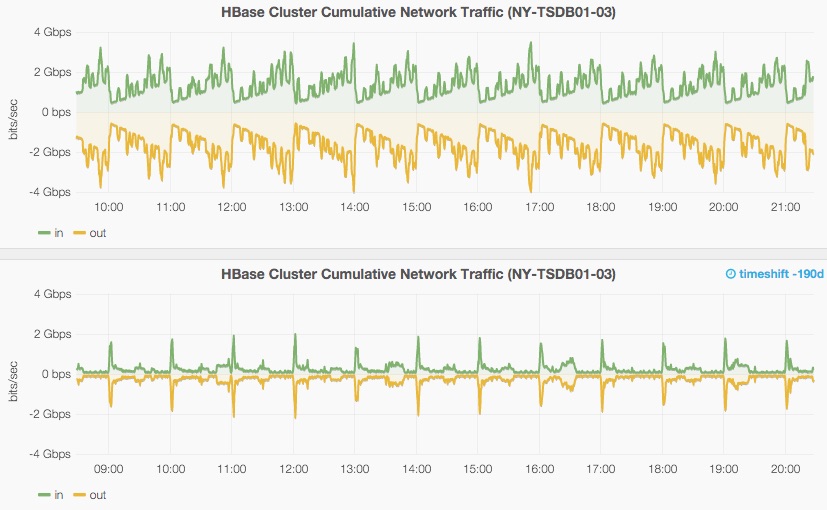
This network traffic was unexpectedly huge considering that our input into OpenTSDB (gzip compressed HTTP JSON) is on average 4 Mbit/sec. Appends can be seen in the hourly seasonality of the above graph. As the row grows over the hour, so do the size of the rows being re-written and and replicated across HDFS and HBase replication.
Zookeeper
We found that for stability we have had to greatly increase the timeouts around zookeeper:
Zookeeper:
tickTime: 30000
maxSessionTimeout: 600000
HBase:
zookeeper.session.timeout: 600000
With low zookeeper timeouts, if operations took a long time or spent a long time in garbage collection, then HBase servers would eject themselves taking the cluster down.
Denormalization, Query Speed, and Last
HBase only has one index. OpenTSDB is optimized around the metric. So for example, querying all the metrics about a host (cpu, mem, etc) is slower than a query against a single metric for all hosts. The HBase schema for OpenTSDB reflects this:
00000150E22700000001000001
'----''------''----''----'
metric time tagk tagv
Since the metric and time fields are the start of the key, and the key is the only thing indexed, the more tags you have on a metric, the more rows that have to be scanned to find your particular host. This reduces query speed.
However, host based views are common. In this schema, they have to multiple metrics, and if those metrics have the host=something tagset, the query gets slower as you add more hosts. Combine that with the number of rows that need to be scanned for longer durations and the queries become untenable.
As an Example, os.cpu has only one tag key host, and about 500 possible values in our environment. To query one year of data (downsampled) to a single host in this metric takes about 20 seconds. If you add more tags it only gets worse (i.e. os.net.bytes which has host, interface, and direction.
We work around this query speed issue to generate views in two ways:
- Redis stores the last value (the last two for counters) for all series. When generating these views, we can get current values for anything nearly instantly. This data is used in Boson’s
/api/hostendpoints and can also be queried directly at/api/last - Denormalize the metrics
To denormalize metrics we put the host name in the metric, and only give it a single tag key / value pair (at least one tag key with a value is required). We use the following argument to tsdbrelay to do this:
-denormalize=os.cpu__host,os.mem.used__host,os.net.bytes__host,os.net.bond.bytes__host,os.net.other.bytes__host,os.net.tunnel.bytes__host,os.net.virtual.bytes__host
This results in a metric like __ny-web01.os.cpu. A year’s worth of data (also downsampled) is queried in ~100 milliseconds as compared to 20 seconds for the normalized metric.
HBase Replication
We have struggled some with HBase replication. The secondary cluster has had to be rebuilt when we found corruption, and also when we upgraded to SSDs. With our most recent case of replication breaking we found that force splitting some of the unbalanced regions on the secondary cluster seems to have fixed in (You can see the unbalance in size via the HBase Web GUI).
When replication breaks, the logs grow rapidly, and drain at a much slower rate then they grow:
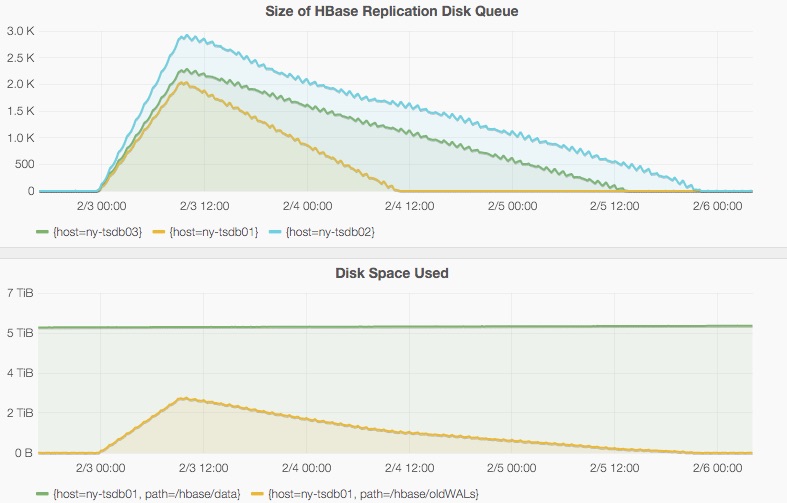
Since replication backing up uses so much disk space, we have to factor in head room for this when sizing the HBase clusters.
Hardware
NY-TSDB0{1,2,3} (Per Sever)
| Area | Details | Utilization |
|---|---|---|
| Model | Dell R620 | |
| CPU | 2x Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz | ~15% |
| Ram | 128 GB Ram (8x 16GB Chips) | 34 GB RSS, Rest Used in File Cache |
| Disk | 2 Spinny OS Disks, 8x SSDs in JBOD (INTEL SSDSC2BB480G4) | Avg Read: 1.6 MByte/sec, Avg Write: 57 MByte/sec |
| Network | Redundant 10Gigabit | ~500 MBit/sec |
NY-BOSUN02 (Also HBase Replica, see previous diagram)
| Area | Details | Utilization |
|---|---|---|
| Model | Dell R620 | |
| CPU | 2x Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz | ~15% |
| Ram | 64 GB Ram (4x 16GB Chips) | 20 GB RSS, Rest Used in File Cache |
| Disk | 2 Spinny OS Disks, 8x SSDs in JBOD (INTEL SSDSC2BB480G4) | Avg Read: 1.1 MByte/sec, Avg Write: 33 MByte/sec |
| Network | Redundant 10Gigabit | ~300 MBit/sec |
Reference Configs
- opentsdb.conf
- tsdbrelay CLI options (In NY)
- haproxy config (In NY)
- Cloudera HBase Non-Defaults
- Cloudera HDFS Non-Defaults
- Cloudera Zookeeper Non-Defaults
How we deploy
The CI framework we use is called TeamCity. We use it to build packages for Deploy scollector, tsdbrelay, to directly deploy Bosun binaries and configurations into production. TeamCity calls each configuration a “build”.
- scollector and tsdbrelay (Linux): We make RPM packages using fpm combined with this script to easily wrap binaries into RPMs. The script reads
mk_rpm_fpmdir.*.txtto manufacture input to FPM. - scollector (Windows): A TeamCity build produces a binary and does the right thing so that it is distributed to our Windows hosts.
- Bosun is deployed directly by TeamCity. We do this because we tend to build pretty often and use branches, so the lag of RPM would be annoying to our developers.
- Our Bosun configuration is kept in a Git repository. TeamCity triggers on changes to this repo, runs tests, pushes the new config to production, then restarts Bosun. (Bosun currently doesn’t have live configuration reloading).
How we Backup
The are three things in and around Bosun that are Backed up:
- Bosun’s Configuration File
- Bosun’s State and Metadata Storage
- The Time Series Data
The configuration file is stored in Git which is backed up independently (we use Gitlab internally). We now use redis to store bosun’s state and metadata. Bosun will use ledis if no redis server is provided, but we haven’t explored how this would be backed up as it is there for small test setups. In redis we use both RDB and AOF for redis persistence:
- RDB allows us to have snapshots of the datastore. These can be restored easily (even for local development).
- AOF allows us persistence across restarts of redis.
Backing up the time series database, in our case OpenTSDB, is one of our pain points. HBase is designed to scale to petabytes. With that much data, a standalone full backup becomes impractical. So HBase isn’t really designed for these sort of backups (See Approaches to Backup and Disaster Recovery in Hbase. This is a shame for us, as we don’t have petabytes of data in another system standalone backups might be an option. Therefore we do the following in place of traditional standalone backups:
- Datapoint level replication: tsdbrelay sends all datapoints to its local and remote cluster (one in NY, one in CO). Although the two HBase clusters are not exactly consistent with each other (different IDs in the database, missing data when a datacenter is out) they are “good enough” copies of each other.
- Restore: Rotating hourly HBase snaphosts
- Backup cluster in the main datacenter: An HBase replica (This is distinct from HDFS replication - that is within a cluster, whereas HBase replication replicates to another cluster).
Without standalone full backups we are frankly a bit afraid of HBase, but we haven’t had any significant data losses since we started using it.
Possible Future Changes
Our largest pain point is using OpenTSDB and HBase. Since we don’t use HBase anywhere else, the administrative overhead eats up a lot of time. Also, OpenTSDB has had some long standing issues that have been difficult, for example counters don’t downsample correctly and our data is in counter format when possible so we don’t lose resolution. That being said we still feel for us it is currently our best option. We will be expanding our two main clusters with two more nodes each (running tsdbrelay, opentsdb, and region servers) to increase space.
We are very interested in InfluxDB. It is written in Go which we are familiar with and has a rapid devlopment cycle. Bosun has it as a backend, and scollector can send to it since it has a OpenTSDB api style endpoint. However, we are waiting for InfluxBD to have a more stable clustering story before we could consider switching to it in production.